


AI & Steam Engines have a lot in common.
AI consumption and energy production are at odds, but history can teach us what to expect. Is there an efficient AI model design? (TL:DR at end)

The hum of steam engines and the server clicks running AI algorithms are bound by a shared principle, and to fully appreciate this we need a quick dive into history. From the dawn of the Industrial Revolution, where steam-powered machines transformed industries, to our current era dominated by artificial intelligence, the pace of innovation has always been driven by energy. This is the undeniable common thread that connect these distinctly different and dynamic periods.
The more energy that was consumed or utilized, led to a higher yield in output.
Monetary economics also follow this principle, in fact, higher income levels and greater energy consumption move in perfect sync, like a well-choreographed routine that's been rehearsed for modern times.
A telling graphic, adequately by Energy for Growth:
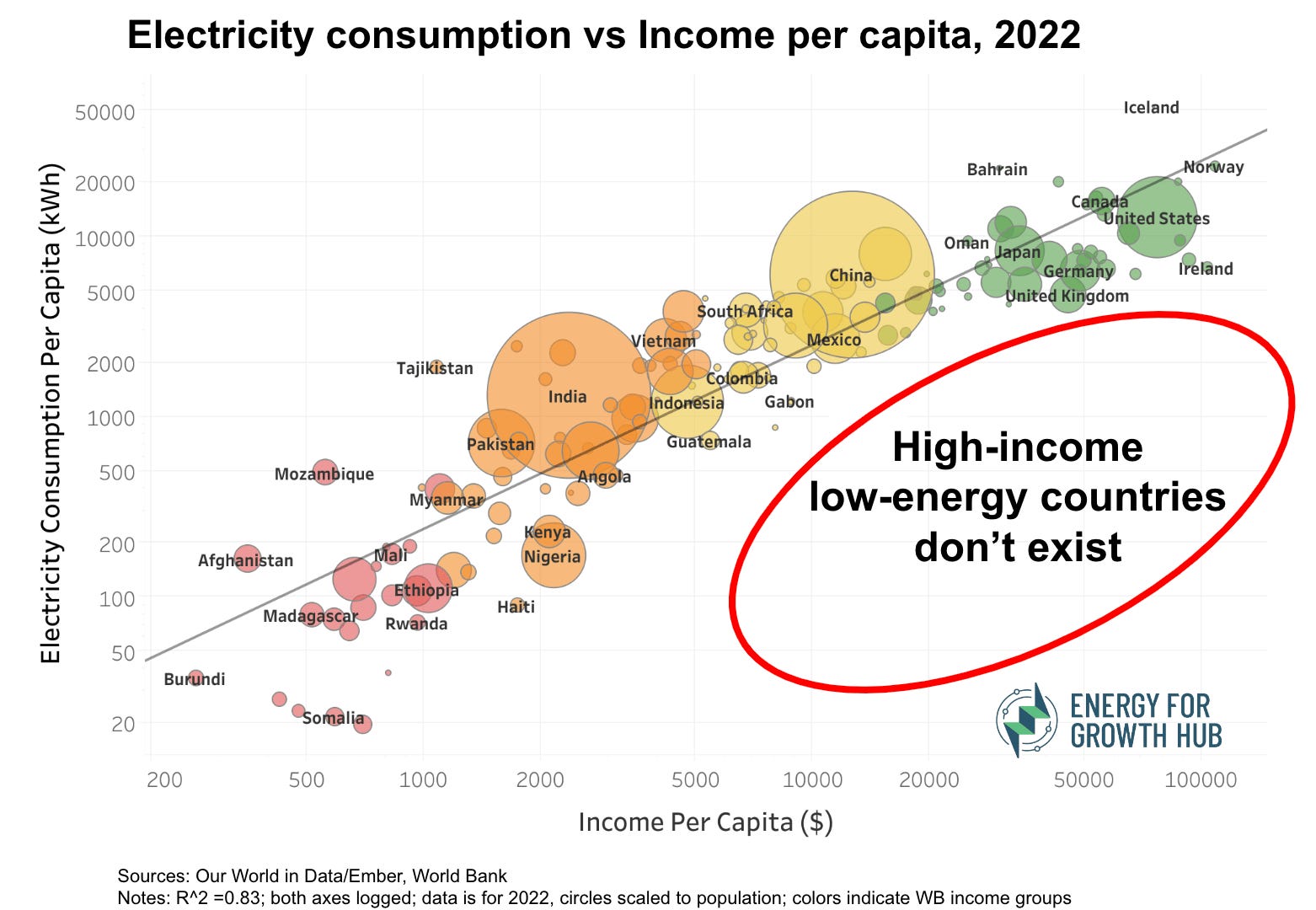
“The graphic is also a stark illustration of energy inequality. People in high-income countries don’t just use a bit more electricity than people living in low-income countries, they use 77 times more.”
[Dig deeper into the data —> interactive version.]
While every investor is familiar with Moore’s Law (often misapplying it to areas such as the cost of renewable energy), hardly anyone knows about the Jevons Paradox. William Stanley Jevons, a 19th century British economist who noticed that as steam engines became more efficient, Britain’s appetite for coal actually increased rather than decrease. At the time, economists were worried that England was running out of coal. Many argued that improved efficiency would quell demand and avert a crisis. Jevon dismissed this logic, correctly concluding that improved efficiency would accelerate demand by promoting increased adoption. Jevon’s Paradox was born: improved efficiency increases consumption.
I lay out this historical precedent to highlight the pressing issue at hand, which is AI’s insatiable hunger for energy consumption (a greater discussion is needed for adjacent natural resources such as water, minerals, land, etc.) and if the US is to position itself as a global leader in AI technology, it will have to amend its energy infrastructure, policy and market mechanisms.
Perspective
The rapid advancement of AI, particularly in the realm of generative AI, has led to an unprecedented surge in energy consumption. Data centers, the backbone of AI operations, are now consuming over 1-2% of global electricity use, but this percentage will likely rise to 3-4% by the end of the decade (see power demand forecast below)1.

To put this into perspective, consider these startling facts:
A single ChatGPT query requires 2.9 watt-hours of electricity, nearly ten times more than a standard Google search (circled)2:

Figure 3. Estimated energy consumption per request for various AI-powered systems compared to a standard Google search
Training a large AI model can produce around 626,000 pounds of carbon dioxide, equivalent to 300 round-trip flights between New York and San Francisco. This figure is nearly five times the lifetime emissions of the average car3.

AI data center capacity is expected to grow at a compound annual growth rate (CAGR) of 40.5% through 2027, with energy consumption increasing at a CAGR of 44.7%4.
These statistics and figures paint a clear picture: as AI becomes more integral to our daily lives and business operations, its energy footprint is expanding at a rate we aren’t prepared for.
What does AI take?
Training an AI model, as we mentioned earlier is highly intensive, and requires using graphics processing units (GPUs), which are power-hungry hardware. As one example, the GPUs that trained GPT-3 are estimated to have consumed 1,300 megawatt-hours of electricity, roughly equal to that used by 1,450 average U.S. households per month. Let’s focus on the model’s direct usage - and generally it’s the two main phases. One is a training phase, where the model learns how to behave by analyzing data. Then comes the inference phase, where the model is in live operation and generates responses based on the prompts it receives.
Prior to Chat-GPT becoming mainstream, big Tech was more transparent about what data and modeling sources, hardware capacities and energy consumption being utilized for their AI models. “For the longest time, companies like Google and Meta were pretty transparent: up until ChatGPT came out, quite honestly,” says Sasha Luccioni, an AI researcher and the climate lead at the AI platform Hugging Face. “In the last year and a half, they’ve gotten a lot more secretive about data sources, training time, hardware, and energy.”
I did some reading on a recently published research paper5 from Hugging Face and Carnegie Mellon University, here’s some interesting snippets:

Figure 5. The tasks examined in our study and the average quantity of carbon emissions they produced (in g of CO2) for 1,000 queries.
Energy and Carbon Intensity by Task Type
Generative tasks are more energy- and carbon-intensive than discriminative tasks.
Image-related tasks consume more energy and produce more carbon emissions than text-only tasks.
Model Architecture Comparison
Decoder-only models are slightly more energy- and carbon-intensive than sequence-to-sequence models of similar size for the same tasks.
Training vs. Inference
Training remains significantly more energy- and carbon-intensive than inference.
Although a single training instance might equate to the energy cost of hundreds of millions of inferences, the high volume of inference calls in deployed models can quickly narrow this gap in overall energy consumption.
Multi-purpose vs. Task-specific Models
Using multi-purpose models for discriminative tasks is more energy-intensive than using task-specific models.
The energy consumption gap widens as output length increases.
Specific Task Comparisons
Question Answering:
BERT-based model: 0.70g CO2eq per 1,000 queries
Multi-purpose models: ~2.35g CO2eq per 1,000 queries (3.3x more)
Text Classification:
BERT-based model: 0.32g CO2eq per 1,000 queries
Flan-T5-XL: 2.66g CO2eq per 1,000 queries (8.3x more)
BLOOMz-7B: 4.67g CO2eq per 1,000 queries (14.6x more)
Sam Altman has been quoted that training GPT-4 cost approximately $100 million. The current generation of models likely cost $1 billion to train. LLM improvement is getting increasingly expensive from a compute, training data size and energy perspective. Some of this will be mitigated by algorithmic efficiency improvement, so each new order of magnitude (OOM) improvement likely requires an 0.5-1 OOM in all three of these. Take this cycle forward by 3-4 more orders of magnitude and you outrun the capacity for companies to sustain further development; models would cost $1-10 Trillion to train!
Where’s the Energy Star sticker?
Designing an AI that uses only the most effective compute based on the task requires a multi-layered, adaptive approach. Here’s a high-level draft design outline:
(1) Modular and hybrid architecture:
Build AI with specialized sub-models for each task (text, images, etc.).
Use a router to analyze queries and direct them to the right module.
(2) Task-driven model selection:
Deploy an automated selector to assess task type, complexity, and quality needs.
Maintain a model catalogue from lightweight to large, choosing the smallest fit.
(3) Dynamic resource allocation:
Allocate compute dynamically using cloud techniques and specialized chips.
Use runtime profiling to monitor energy, latency, and performance.
(4) Adaptive precision & distillation:
Use quantized or distilled models for lower precision tasks.
Switch between full and lower precision based on quality need.
(5) Feedback & performance analytics:
Log and analyze each invocation to refine model selection and resource allocation.
Use reinforcement learning with efficiency metrics as rewards.
Or maybe just make it easier on us all and just slap on an energy star sticker, like when we purchase an electric device like a phone, dishwasher or toaster. The team at HuggingFace is leading an effort called the AI Energy Score project developing a system for scoring AI model deployment that will act as a guide for different tasks based on their energy efficiency and to analyze the effect of implementation choices on the downstream energy usage of different models.

There are other ongoing collaborative efforts, one noteworthy example being the work of Vijay Gadepally, a senior scientist at MIT Lincoln Laboratory, and Prof. Devesh Tiwari of Northeastern University. Together, they built a software tool called Clover6 that incorporates carbon intensity as a parameter. This allows it to recognize peak energy periods and automatically make the appropriate adjustments, such as using a lower-quality model or opting for lower-performing compute horsepower. 'With this experiment, we reduced the carbon intensity for different types of operations by about 80% to 90%,' Gadepally said.
Given the immense potential, why don’t we see more of a shift toward sustainable techniques? It's primarily an issue of misaligned incentives. There's a rat race for building bigger models, causing almost every secondary consideration to be neglected.
The Broader Environmental Impact
While the energy consumption of AI is significant, its carbon footprint impact extends far beyond energy. The complete end-to-end lifecycle of AI technologies, from production to disposal (which is lacking transparency), presents a multifaceted challenge:
Electronic Waste: The demand for more powerful hardware to support AI operations is contributing to a surge in electronic waste1.
Water Consumption: Data centers require vast amounts of water for cooling. In water-stressed regions, this can exacerbate existing shortages.
Land Use: The rapid expansion of data centers is transforming landscapes, sometimes at the expense of residential areas or natural habitats.
Resource Extraction: The production of AI hardware involves the extraction of minerals and other natural resources, which can have detrimental effects on the environment. Mining activities can lead to habitat destruction, soil erosion, and water pollution.
Analysts project the rise of data center carbon dioxide emissions will represent a “social cost” of $125-140B (health issues, environment degradation, economic losses due to climate impact). Big Tech indicates continued confidence in driving down energy intensity but less confidence in meeting absolute emissions forecasts on account of rising demand.
+TL:DR
LLMs will get smaller and efficient compute will reign as catalyst driver. Models will be task-driven and segregated based on specific inputs vs weighted outputs. Countries with mature (and decentralized adaptive) energy policies will lead as global AI leaders. Jevon’s paradox will hold true and AI consumption rates will continue to soar.
AI is poised to drive 160% increase in data center power demand | Goldman Sachs
Alex de Vries (2023). The growing energy footprint of artificial intelligence. Joule, Volume 7 (Issue 10), Page range. https://doi.org/10.1016/j.joule.2023.03.365
AI’s Environmental Impact: Growing Concerns Amidst Tech Advancements – The Observer.
IDC Report Reveals AI-Driven Growth in Datacenter Energy Consumption, Predicts Surge in Datacenter Facility Spending Amid Rising Electricity Costs
Luccioni, Alexandra Sasha, et al. "Power Hungry Processing: Watts Driving the Cost of AI Deployment?" arXiv.org, 15 Oct. 2024, https://arxiv.org/abs/2311.16863.
Gadepally, V., & Tiwari, D. (2023). Reducing Carbon Intensity for Computational Operations. arXiv.org, 31 Aug. 2023, https://arxiv.org/pdf/2304.09781